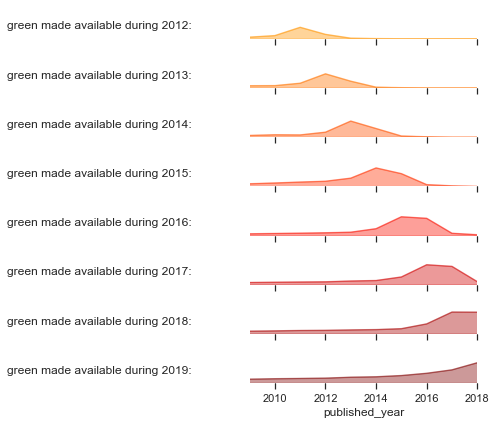
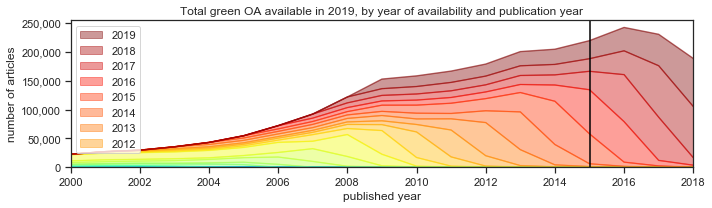
We’d like to share one of the fun parts of our recent preprint. It’s fun because the concept of Date of Observation helps to untangle issues around embargoes — and also because we think we came up with a neat way to explain what is otherwise a fairly complicated concept, and hopefully make it accessible to everybody.
See what you think — here is our description of the Date of Observation, from section 3.3 of the preprint:
Let’s imagine two observers, Alice (blue) and Bob (red), shown by the two stick figures at the top of the figure:
Alice lives at the end of Year 1–that’s her “Date Of Observation.” Looking down, she can see all 8 articles (represented by solid colored dots) published in Year 1, along with their access status: Gold OA, Green OA, or Closed. The Year of Publication for all eight of these articles is Year 1.
Alice likes reading articles, so she decides to read all eight Year 1 articles, one by one.
She starts with Article A. This article started its life early in the year as Closed. Later that year, though–after an OA Lag of about six months–Article A became Green OA as its author deposited a manuscript (the green circle) in their institutional repository. Now, at Alice’s Date of Observation, it’s open! Excellent. Since Alice is inclined toward organization, she puts Article A article in a stack of Green articles she’s keeping below.
Now let’s look at Bob. Bob lives in Alice’s future, in Year 3 (ie, his “Date of Observation” is Year 3). Like Alice, he’s happy to discover that Article A is open. He puts it in his stack of Green OA articles, which he’s further organized by date of their publication (it goes in the Year 1 stack).
Next, Alice and Bob come to Article B, which is a tricky one. Alice is sad: she can’t read the article, and places it in her Closed stack. Unbeknownst to poor Alice, she is a victim of OA Lag, since Article B will become OA in Year 2. By contrast, Bob, from his comfortable perch in the future, is able to read the article. He places it in his Green Year 1 stack. He now has two articles in this stack, since he’s found two Green OA articles in Year 1.
Finally, Alice and Bob both find Article C is closed, and place it in the closed stack for Year 1. We can model this behavior for a hypothetical reader at each year of observation, giving us their view on the world–and that’s exactly the approach we take in this paper.
Now, let’s say that Bob has decided he’s going to figure out what OA will look like in Year 4. He starts with Gold. This is easy, since Gold article are open immediately upon publication, and publication date is easy to find from article metadata. So, he figures out how many articles were Gold for Alice (1), how many in Year 2 (3), and how many in his own Year 3 (6). Then he computes percentages, and graphs them out using the stacked area chart at the bottom of the figure. From there, it’s easy to extrapolate forward a year.
For Green, he does the same thing–but he makes sure to account for OA Lag. Bob is trying to draw a picture of the world every year, as it appeared to the denizens of that world. He wants Alice’s world as it appeared to Alice, and the same for Year 2, and so on. So he includes OA Lag in his calculations for Green OA, in addition to publication year. Once he has a good picture from each Date Of Observation, and a good understanding of what the OA Lag looks like, he can once again extrapolate to find Year 4 numbers.
Bob is using the same approach we will use in this paper–although in practice, we will find it to be rather more complex, due to varying lengths of OA Lag, additional colors of OA, and a lack of stick figures.